G
Cadence© Load Balancing Software (LBS) Distribution Method
This chapter describes how to set up and use distributed processing for job simulation in Virtuoso using the Cadence Load Balancing Software (LBS).
- Introduction to LBS Mode
- System Administration of Distributed Jobs with LBS
- Setting up DRMS in LBS Distribution Method
- Validating the LBS Distributed Processing Setup
- Submitting Simulation Jobs in LBS Distribution Method
- Monitoring Distributed Jobs in LBS Method
- Debugging an LBS Distributed Processing Setup
- Troubleshooting FAQs
Introduction to LBS Mode
Distributed processing is the setup used for distribution of a program, task, or job across multiple hosts. In such a setup, the multiple hosts work together to complete the task or job. See System Administration of Distributed Jobs with LBS for more information.
By default, LBS uses the Cadence Queue Manager (cdsqmgr) to distribute jobs in the distribution queues. In addition, it provides a built-in hook into the following third-party Distributed Resource Management System (DRMS) tools:
- An LBS client library: Used by Cadence applications to interact with the LBS server process.
- An LBS server program: Uses the LBS client library provided by the DRMS to interact with the DRMS cluster.
Therefore, the LBS server process is considered a DRMS client application.
System Administration of Distributed Jobs with LBS
This section contains information that system administrators need to configure LBS and the distributed processing clusters. To use distributed processing successfully, ensure that your setup follows the requirements described in the following sub-sections:
Common LBS Setup Requirements
You must ensure that your site meets the following list of basic requirements or assumptions so that the distributed processing software works smoothly:
-
To submit a job, you must have an account and a home directory on the submission host and the execution host.
Example: If a usermorrisonwho submits a job frommachine Atomachine Bdoes not have an account onmachine B, the submit request formorrisonfails. - You must have access to the OS specific Cadence® software on every execution host that might receive a job from you.
-
The directory on your local machine from which you run the distributed processing software must be exported if you are using the
v/net,/home, or/hm. Network mode also assumes that your working directory, and all your design data are under your account and are mirrored. Whenever the remote job references a path, that path goes directly back to the original directory on your home machine. -
The
uid(UNIX user ID) of a user must not change when the user switches from one machine to another. For example,uidof8819must not identify usermorrisononmachine Aand userdoeonmachine B. -
To submit jobs, all users must have write-access to the
/tmpfile system on the execution and submission hosts. The job submission and execution processes create certain temporary files that are saved in the/tmpfile system. -
The setup considers that all files – input, output, error, and any command or OCEAN files – have absolute or relative locations, depending on whether they are preceded by a
/. All relative locations are searched relative to the working directory of the job. Ensure that you specify the correct path for all files. -
The directory structure on the home machine and the remote machine must be identical. For example, if the working directory of the job on your machine is
/net/salmon/u1/morrison, the design directory on the execution machine must be/net/coho/u1/morrison. If the directory structure does not match onsalmonandcoho, use a link to mirror the directory structure on the home machine.
Shell Variables for LBS Distribution Method
The LBS distribution software supports the cdsqmgr, LSF, and SGE DRMS. To distribute and process jobs in the LBS method, you need to set the following environment variables based on the DRMS that you use for each distributed processing client machine:
|
Set this to the LBS master host that controls job distribution to the queues. Your system administrator can help in this setup. setenv LBS_CLUSTER_MASTER LBS_master_host
LBS_master_host is the host on which the LBS queue manager runs for controlling job distribution to the queues. Take your system administrator’s help in setting this up. By default, LBS uses the
You can skip setting the |
|
|
Set this to define the load balancer that you want to use with LBS. For this, add one of the following commands in your See System Requirements for cdsqmgr Setup. |
The variable values that you specify differ based on whether you use LBS with cdsqmgr, or LBS with third-party DRMS. However, ensure that you set the appropriate variables based on the DRMS that you use. If you specify none of these variables, you can use distributed processing in the command-line mode only.
Additional Requirements
In addition to the common and DRMS-specific requirements, ensure that your system administrator also considers the following:
Time Clock Consideration
All users in a cluster must synchronize the clocks on all computers. Failure to synchronize the clocks can cause errors when you submit jobs. For example, machine Y’s clock reports the time as 11:50, and machine Z’s clock reports the time as 12:00. If a user on machine Y submits a job to machine Z to run ‘Today’ at 11:55, machine Z cannot run the job. The simulation will fail to run on machine Z because the specified run time occurred before the job was submitted.
Network Mode Consideration
To run the distributed processing software, the default mode is the Network Mode. Network mode assumes that your home account is mirrored (linked) on every remote machine on which you might run a job, using commands such as, /net, /home, or /hm. Network mode also assumes that your working directory and all your design data are under your account and are mirrored. Whenever the remote job references a path, that path goes directly back to the original directory on your home machine.
Setting up DRMS in LBS Distribution Method
This section describes the various DRMS-specific settings that are required for processing jobs using the LBS distribution method. You can set up your LBS setup depending on the DRMS that you choose.
- System Requirements for cdsqmgr Setup
- System Requirements for LSF Setup
- System Requirements for SGE Setup
System Requirements for cdsqmgr Setup
LBS cdsqmgr is a Cadence load balancing software that helps you set up a simple distributed system for multiple users based on the configuration file that you specify. It helps to run distributed processing jobs in queue mode.
Using LBS with cdsqmgr, you can set up any number of queues (collections of host machines) and hosts per queue. Each queue has a job-per-host limit. LBS cdsqmgr dispatches jobs to the hosts in the order that you specify.
Job distribution using LBS cdsqmgr is supported by the Cadence analog simulator Spectre, APS, XPS, and mixed-signal simulator AMS.
Setting up a site for an LBS system with cdsqmgr involves one of the following:
Using cdsqmgr with remote shell (rsh)
To set up distributed processing with LBS cdsqmgr, ensure that you have the required system administrator rights or root permissions, and do the following:
- Create the config file.
- Check the host requirements. Ensure the following:
- Start the daemon process.
- Set up the UNIX environment for distributed processing users.
- Run the configuration testing script.
rsh to communicate between the hosts. Therefore, no additional settings are required to run rsh.Creating the Config File
Cluster configuration files can have any name and reside in any location. This file contains names of queues, machines in queues, number of hosts in a queue, names of hosts in a queue, and the job limit of individual hosts. The syntax for these files is as follows:
queue_1_name N_-_number_of_hosts_in_queue_1
host_1 job_limit_for_host_1_on_queue_1
host_2 job_limit_for_host_2_on_queue_1
...
host_N job_limit_for_host_N_on_queue_1
queue_2_name N_-_number_of_hosts_in_queue_2
host_1 job_limit_for_host_1_on_queue_2
host_2 job_limit_for_host_2_on_queue_2
...
host_N job_limit_for_host_N_on_queue_2
...
queue_n_name N_-_number_of_hosts_in_queue_n
host_1 job_limit_for_host_1_on_queue_n
host_2 job_limit_for_host_2_on_queue_n
...
host_N job_limit_for_host_N_on_queue_n
For example, the contents of a sample configuration file lbs.config are as follows:
************************ lbs.config ***************************
queueA 2
noi-user1 3
noi-user2 2
queueB 3
noi-user1 4
noi-user2 2
noi-user3 3
****************************************************************
Place this file in your $HOME.
In the above configuration file, queueA and queueB are the names of two queues. The first statement queueA 2 indicates that the queue queueA has two hosts. These hosts are noi-user1 and noi-user2. The statement noi-user1 3 indicates that the host noi-user1 can handle a maximum of 3 jobs. Similarly, host noi-user2 can handle a maximum of 2 jobs.
Checking the Host Requirements
-
For LBS
cdsqmgrto work smoothly, you must be able to usershto log in to another host without a password. If you receive a prompt for a password, disable the password. -
Ensure that all host machines can access the Cadence tools. To check if the path to the Cadence tool is available on each host, log in to all the hosts individually and run the following command in the Unix terminal window:
> which spectre > which virtuoso
-
Use
rloginto log in to each host and check if the host passes thecheckSysConftest. The following command ensures that the machine has all the required patches for running the tool.
For example, if you are running Virtuoso IC6.1.8, use the following command:<ic_install_path>/tools/bin/checkSysConf <ic_install_version>checkSysConf IC6.1.8
Repeat this test on each host for all Cadence tools (like simulators). For more details, refer to the Cadence article: Running checkSysConf to verify system patch levels. - Ensure that all hosts are connected to a common directory structure so that the project work area and the simulation directories are visible to each host.
Starting the Daemon
To run cdsqmgr on the identified cluster master, do the following:
-
Identify the cluster master, which is the host on which the
daemonneeds to be run. If the master host isnoi-user1,rloginto hostnoi-user1.> rlogin noi-user1
-
Kill any
cdsqmgrprocess that is already running under the root directory or any other account. Use the following command to find the process:Unix> ps -aef |grep cdsqmgr
Running this command may result in an output as follows:userA 14494 1 0 19:05 ? 00:00:00 /ccstools/cdsind1/Software/IC618ISR_lnx86/tools/bin/32bit/cdsqmgr lbs.config
Here,cdsqmgris already running withPID14494. To kill thisPID, use the following command:> kill 14494
-
Kill any
cdsNameServerprocess that is already running under the root directory or any other account. To do this, use the following commands:Unix> ps -aef |grep cdsNameServer userA 764 1 0 Jul30 ? 00:00:00 /ccstools/cdsind1/Software/IC618ISR_lnx86/tools/bin/32bit/cdsNameServer userA 4181 14330 0 20:47 pts/8 00:00:00 grep cdsNameServer
Here, thecdsNameServeris already running withPID764. To kill thisPID, use the following command:Unix> kill 764
-
Start
cdsqmgras a root user on this master host (noi-user1)by providing the full path to the queue configuration file. The syntax is as follows:cdsqmgr <full_path_to_config_file>/lbs.config
For example:Unix> cdsqmgr /home/user/lbs.config
cdsqmgr from a user account on a cluster master machine, only that user will be able to submit jobs through that cdsqmgr. This is not recommended because jobs of individual users will not be queued together, and as a result, shared resources might not be used optimally.UNIX Environment Setup for LBS Distribution Method
To prepare your UNIX environment:
- Ensure that your setup meets the common setup requirements. See Common LBS Setup Requirements.
-
Set the following in the
.cshrcfiles for every user environment that intends to run the distributed simulation with LBS:setenv LBS_CLUSTER_MASTER
Here,LBS_master_hostLBS_master_hostis the host on which thecdsqmgrdaemon is running with root permissions. See Starting the Daemon.
For example:Unix> setenv LBS_CLUSTER_MASTER noi-user1
In the above command,noi-user1is set as the cluster master in every user environment.
Configuration Testing Script
To test your setup for some common mistakes, run the adptest script. The script, together with the other Cadence binaries, is available at <ic_install_path>/tools/dfII/bin. To run the script, type the following at the terminal prompt:
adptest
The script displays messages in the same window where you run the script.
>> BEGIN Analog Design Environment Distributed Processing Setup Test Testing for existence of LBS_CLUSTER_MASTER variable... PASSED. Testing opening of Analog Design Environment Job Server... Launching Analog Design Environment job server... Analog Design Environment job server has initialized! PASSED. Please be patient - the remaining portion of the test takes some time. Testing job submission to host `noi-user3' on queue 'queueB'... PASSED. Testing job submission to host 'noi-user2' on queue 'queueB'... PASSED. Testing job submission to host 'noi-user1' on queue 'queueB'... PASSED. Testing job submission to host 'noi-user2' on queue 'queueA'... PASSED. Testing job submission to host 'noi-user1' on queue 'queueA'... PASSED.
END Analog Design Environment Distributed Processing Setup Test
t
<<
Using cdsqmgr with secure shell (ssh)
By default, Virtuoso uses rsh to utilize any distribution processing system. However, several organizations may block rsh and allow only the ssh setup, because of its higher security. You can configure Virtuoso to use ssh for distributed processing.
To configure Virtuoso for using ssh, ensure that you have the required root permissions or administrative rights, and do one of the following:
- Configure Remote Hosts to Accept ssh Connection without a Password
- Edit the cdsRemote.scr File
- Set Virtuoso Environment Variable in the .cdsinit File
Configuring Remote Hosts to Accept ssh Connection Without a Password
For Virtuoso distributed system to work with ssh, you need to use ssh to log in to the execution hosts without any password. For example:
shyam@noi-userA$ ssh noi-userB
If you have ssh access on the execution hosts without any password, you immediately get a prompt on that machine as follows:
Last login: Mon Aug 19 17:23:58 2019 from noi-userA.cadence.com
------------------------------------------------------------------
This Cadence-owned computer system and Cadence's computer network are made
available to you for the purpose of conducting authorized company business.
You have no reasonable expectation of privacy with regard to content created,
stored and/or transmitted on this system, except as provided by applicable law.
Cadence may - at any time, for any reason and with or without notice - search,
monitor and inspect this computer and network to the full extent permitted by
applicable law.
==================================================================
/usr/local/rc/cadence.login: No such file or directory.
[userA@noi-userB ~]$
If you do not configure ssh to work without password, the system may give you a message as shown below or may ask for the password.
The authenticity of host 'noi-userB (172.23.65.158)' can't be established.RSA key fingerprint is ac:d9:69:47:10:8d:7f:83:86:53:5f:10:07:e3:20:82.
Are you sure you want to continue connecting (yes/no)?
You need to contact your IT department for creating a setup in which users can use ssh to log in to execution hosts without any password.
Alternatively, create an ssh setup that does not require a password. This method creates a private or public key and registers the execution hosts. Ensure that you have ssh installed on the machines. To create this setup, do the following:
- Create a public or private key.
- Copy the public key file as authorized_keys and add the remote host in the known_hosts list.
- Locate the known_hosts files to validate addition of specified host.
- Add more execution hosts in the known_hosts file.
To create a public or private key, do the following:
-
Run the following Unix command:
unix> cd $HOME/.ssh
-
Run the following Unix command to create a public or private RSA key pair:
unix> ssh-keygen –t rsa userA@noi- user A ~/.ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/userA/.ssh/id_rsa):
-
Press
Enter. If anid_rsafile already exists, you get a prompt to overwrite the file (Overwrite (y/n)?). Typeyand pressEnterto overwrite the file. -
Press
Enteron the next prompt (Enter passphrase (empty for no passphrase):), to keep the passphrase null:[userA@noi-userA ~/.ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/userA/. ssh/id_rsa) Enter passphrase (empty for no passphrase): |
-
Press
Enteron the next prompt (Enter same passphrase again:), pressEnter.(userA@noi- userA -/. ssh ]$ ssh- keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/ userA /.ssh/id_rsa) Enter passphrase (empty for no passphrase): Enter same passphrase again:
The following message appears:[ user A @noi- userA ~/.ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/ userA .ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/ userA /. ssh/id_rsa. Your public key has been saved in /home/ userA /.ssh/id_rsa.pub. The key fingerprint is:
e2:5a:5d:d5:d6:cc:d7:d6:28:61:20:a4:51:27:71:63 userA @noi- userA The key's randomart image is:
+-- [ RSA 2048]----+ | .0*.E.0 | | 0 * 0 0 =0| | . 0 + 0| | . 0 ..| | . S . | | . 0 . | | 0 . | | 0 | | . | +------------------+ [ userA @noi- userA ~/.ssh]$
The preceding procedure generates two files:id_rsaandid_rsa.pubin your~/.sshdirectory.
Adding remote hosts in the known_hosts list
To add the remote hosts in the known_hosts list, copy the id_rsa.pub public key file as authorized_keys. For this, run the following command:
unix> cat id_rsa.pub | ssh userA@noi-userB "mkdir -p ~/.ssh && chmod 700 ~/.ssh && cat >> ~/.ssh/authorized_keys"
You receive a prompt to confirm your connection to the host:
(userA@roi-userA ~/.ssh|$ cat id_rsa.pub | ssh userA@noi-userB "mkdir p -/.ssh && chmod 700 ~/.ssh && cat » ~/.ssh/authorized_keys'
The authenticity of host noi-userB (172.23.65.158) can't be established.
RSA key fingerprint is ac:d9:69:47:10:8d:7f:83:86:53:5f:10:37:e3:20:82.
Are you sure you want to continue connecting (yes/no)?
Type yes and press Enter. You are asked for the user password (userA).
[ userA@noi-userA ~/.ssh]$ cat id_rsa.pub | ssh userA@noi-userB "mkdir -p ~/.ssh && chmod
The authenticity of host 'noi-userB (172.23.65.158)' can't be established.
RSA key fingerprint is ac:d9:69:47:10:8d:7f:83:86:53:5f:10:07:e3:20:82.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'noi- userB,172.23.65.158' (RSA) to the list of known hosts.
userA@noi- userB's password: |
After providing the password, the host noi-userB is added into the known_hosts file.
[ userA@noi-user A ~/.ssh]$ cat id_rsa.pub | ssh userA@noi-userB "mkdir -p ~/.ssh && chmod 700 ~/.ssh && cat » ~/.ssh/authorized_keys"
The authenticity of host 'noi- userB (172.23 65.158)' can't be established.
RSA key fingerprint is ac:d9:69:47:10:8d:7f:83:86:53:5f:10:07:e3: 20: 82.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'noi-userB, 172.23.63.158' (RSA) to the list of known hosts.
userA@noi-userB's password:
[ userA@noi-userA ~/.ssh]$
Now, if you use ssh to connect to noi-userB, you will not get any query or prompt for entering a password.
Validating the addition of new hosts
You will now find two more files, authorized_keys and known_hosts that are created in the .ssh directory. Run ll in the directory to find these files.
[userA@noi- user A ~/.ssh]$ ll
total 16
-rw-r--r-- 1 userA cadencel 399 Aug 21 15:36 authorized_keys
-rw------- 1 userA cadencel 1671 Aug 21 15:2G id_rsa
-rv-r--r-- 1 userA cadencel 399 Aug 21 15:20 ld_rsa.pub
-rw-r--r-- 1 userA cadencel 406 Aug 21 15:36 known_hosts
[userA@noi- userA ~/.ssh]$
Open the known_hosts file and validate that the host noi-userB is added.
Adding more hosts in the known_hosts file
Repeat the command in
unix> cat id_rsa.pub | ssh userA@noi-user1 "mkdir -p ~/.ssh && chmod 700 ~/.ssh && cat >> ~/.ssh/authorized_keys"
Open the known_host file. You will find the noi-userB and noi-user1 hosts added to it.
noi-userB, 172.23.65.158 ssh-rsa AAAAB3NzaClyc2EAAAABIwAAAQEA5tUYB]hc3j+CLqydfvZ+DL5pUB9rqRfiXzS31lDyWFAN/khLQSKy3Xg0pxbNRWZCcXnqnv2U0LGvTgIXe84spNsUYpYqoTn+3DlLn8MaqiEUK47oCB2WvW+tiDvLVMruCXy4XGi+hDwdtEEEgC++gwfJqONE5M6zRNh29pt65Qt3ZKzP3kPz340sqmTMkEluok8YMMa7TS+IuxjQphUGYTrTakUV3fqSSU+DZH43qdlplUUZKbPXgk3jK08suKsBdgXSpc9ey0oMswlmvu07THDqZexqMgScWqeERExH0850d5she3vvQ/BiJu525/Xa3U7sR3LvuK10nDWPCXtUQ==
noi- user1, 172.23.65.27 ssh-rsa AAAAB3NzaClyc2EAAAABIwAAAQEA5tUYBjhc3}KLqydfYZ+DL5pUB9rqRfiXzS31lDyWFAN/khLQSKy3Xg0pxbNRWZCcXnqYlV2U0LGvTgIXe84spNsUYpYqoTn+3OlLn8MaqiEtiK47oCB2WvW+tlOvLVMniCXy4XGi<-hOwdtEEEgC++^/3qONE5M6zRNh29pt65Ot3ZKzP3kPz340sqmTMkEluok8YMMa7TS+IuxjQphUGYTirakUV3fqS5U+DZfi43qdlplUUZKbPXgk3jK08suKsBdgXSpc9ey0oMswlmvu07THDqZexqMgScWqeERExH08 50d5she3vvQ/BiJu525/Xa3U7sR3LvuK10nDWPCXtUQ==
Editing the cdsRemote.scr File
By default, the cdsRemote.scr file, which is available in the $CDSHOME/share/cdssetup/<username>/ directory, specifies the default configuration as follows:
remoteSystem=rsh // Default configuration
#remoteSystem=ssh
To use ssh instead of rsh, make the following changes in the cdsRemote.scr file:
#remoteSystem=rsh // To configure for generic ssh
remoteSystem=ssh
This enables the remoteSystem=ssh switch for the ssh method.
#----cdsRemote.scr = (/ccstools/cdsindl/Software/share/cdssetup/cdsRemsh)----#
--------------------------------------------------------------------------------- exec "$remsh" “$rhostName" $noStdinFlag "$@" } #---------------------------------------------------------------------- # Main program #---------------------------------------------------------------------- remoteSystem=rsh #remoteSystem=ssh # uncomment this line to configure for generic ssh
operation="$l"; shift case "${remoteSystem}-${operation}" in rsh-shell)
ClassicRsh "$@";;
rsh-copy)
exec rcp "$@";;
ssh-shell)
exec ssh "$@";;
ssh-copy)
exec scp "$@";;
*)
Setting Virtuoso Environment Variable in the .cdsinit File
To use ssh, set the following in your .cdsinit file:
envSetVal("asimenv.distributed" "remoteShell" 'string "ssh")
You can now run distributed LBS with ssh in Virtuoso.
Follow the steps in the “Using cdsqmgr with remote shell (rsh)” section to set up and configure LBS with rsh.
Additional Requirements for LBS
-
Check if
LBS_CLUSTER_MASTERis set. IfLBS_CLUSTER_MASTERis not set, then set this variable appropriately and proceed to the next step. -
Check if
LBS_BASE_SYSTEMis set. IfLBS_BASE_SYSTEMis set, ensure that it is set toLBS_DEFAULT. -
Check if
cdsqmgris running on the machine specified asLBS_CLUSTER_MASTER. Ifcdsqmgris not running, killcdsNameServerand re-runcdsqmgrfrom the root. See Starting the Daemon. -
Ensure that only one copy of
cdsqmgris running from the root account. If multiple copies ofcdsqmgrare running, kill all the copies andcdsNameServer, and reruncdsqmgras root. See Starting the Daemon. -
Check if
cdsNameServeris running onLBS_CLUSTER_MASTER. If it is not running, kill anycdsqmgrthat may be running and reruncdsqmgras root. See Starting the Daemon. -
Ensure that you rerun
cdsqmgrandcdsNameServerwhenever thequeueConfigfile used bycdsqmgris modified. See UNIX Environment Setup for LBS Distribution Method. -
Ensure that all machines specified in the
queueConfigfile are active and do not prompt you to enter the password at login. You can usepingto check if the machines are active. To check password-related issues, typeremsh <any_host_in_queue> pwdin the submission host terminal. -
Take your system administrator’s help to ensure that the timestamp of all the machines specified in
queueConfigfile matches with the machine specified asLBS_CLUSTER_MASTER.
System Requirements for LSF Setup
In addition to the Common LBS Setup Requirements, ensure that the following initial setup requirements are met before you submit jobs to hosts that run the LBS distributed processing method with LSF. The LSF cluster must already be installed and configured as per the LSF installation guide. To troubleshoot any LSF installation issue, contact the LSF system administrator at your site.
Ensure that the LSF server version at your site is compatible with the LSF client version used by the Cadence LSF interface. If the LSF server and client versions (the version of LSF libraries integrated with Cadence LSF daemon) do not match and are not compatible, contact the LSF vendor (
Compare the output of these commands:
-
$cdsfrb_lsf -version
The output determines the version of the LSF-provided client library used by thecdsfrb_lsfdaemon. -
$lsid –version
The output represents the minimum LSF cluster version for the integration.
You must set the environment variable LBS_BASE_SYSTEM to LBS_LSF in each shell from which you start a Cadence tool to submit jobs.
setenv LBS_BASE_SYSTEM LBS_LSF
Here, LBS_LSF specifies that you want to use the LSF load balancer.
Additional Requirements for LSF
-
Ensure that
LBS_CLUSTER_MASTERis not set. -
Ensure that
cdsqmgris not running. -
Ensure that
LBS_BASE_SYSTEMis set toLBS_LSF. -
Check if
LSFsoftware is installed and running on this machine. Ensure thatsbatchd,lim,pimandresdaemons are running on this machine, and that you can run thelsload,bjobsandbsubpwdcommands without generating any errors. -
Ensure that machines specified in the LSF cluster are active and do not prompt you to enter a password when you log in to these machines. Use
pingto check if the machines are active. To check for password-related issues, typeremsh <any_host_in_queue> pwdin the submission host terminal.
In the LSF setup, the Job Policy Setup form displays a few additional fields as shown in the following figure:
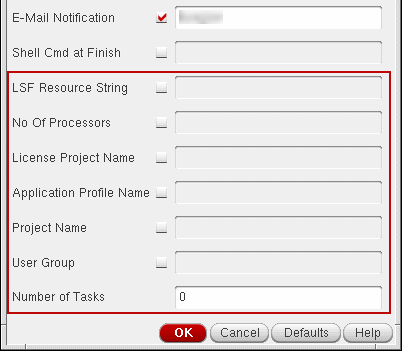
-
LSF Resource String: Lets you specify the additional resource requirements for the job that are not available as separate options in the Job Policy Setup form – for example,
mem(available memory),swp(available swap space),pg(paging rate). You can specify the additional resource requirements using a valid LSF resource requirement string. For more details and examples of LSF resource requirement string, refer to Resource Requirement String Format. - No of Processors: Lets you specify the number of parallel processors that you must use to run the submitted job. To use the value specified in this field, select the check box next to this field.
- License Project Name: Lets you specify the name of the license project. To use the value specified in this field, select the check box next to this field.
- Application Profile Name: Lets you specify the name of an application profile that you must use to run the submitted job. To use the value specified in this field, select the check box next to this field.
- Project Name: Lets you specify the name of a project associated with the job. To use the value specified in this field, select the check box next to this field.
-
User Group lets you assign the submitted jobs to the groups of user.
- Number of Tasks: Lets you specify a numerical value that indicates the number of tasks in which TransNoise jobs needs to be divided for simulation. This option appears if you select the Transient Noise option for the tran analysis in the Choosing Analyses form. To achieve better performance with Transient Noise, specify the values of this field in a way that the number of runs divided by the number of tasks results in a whole integer value.
Resource Requirement String Format
LSF uses the resource requirement string to select hosts for remote execution and job execution. For example, you can specify the following resource requirement string in the <DRMS> Resource String field, where <DRMS> stands for LSF :
select[swp > 50 && mem > 500]rusage[mem=100]
This resource requirement string runs a job only on a host that has 50 MB or more of available swap space and 500 MB or more of available memory, and also reserves 100 MB memory for the job.
The resource requirement string can have the following sections:
-
Selection section (
select) – Specifies the criteria for selecting hosts for a job. -
Ordering section (
order) – Indicates how the hosts that meet the selection criteria must be sorted. -
Resource usage section (
rusage) – Specifies the expected resource consumption of the job. -
Job spanning section (
span) – Indicates if a parallel batch job must span across multiple hosts. -
Same resource section (
same) – Indicates that all processes of a parallel job must run on the same type of host.
See Table G-1 for examples of each section.
For more information about resource requirement strings in LSF, see the product documentation for LSF at
-
If the resource requirement string cannot be satisfied, the job will not run and the results are undefined.
For example, if you specifyselect[tmp>100]as the resource requirement string and no machine in the queue has100 MBor more of memory in/tmp, the job will not run and no message will be displayed in the CIW window. -
If you specify a resource requirement string that conflicts with an option that you specify in the Job Policy Setup form, the job does not run and the results are undefined.
For example, if you specify the hosttezas the host to run the job under the Hosts section of the Job Policy Setup form and also select theOnly Use Selected Hostoption and also specify the host name aspvsol7in the LSF Resource String field, the job will not be run and the status of the job will be undefined.
Related Topic:
System Requirements for SGE Setup
In the SGE setup, the Job Policy Setup form displays a few additional fields as shown in the following figure:
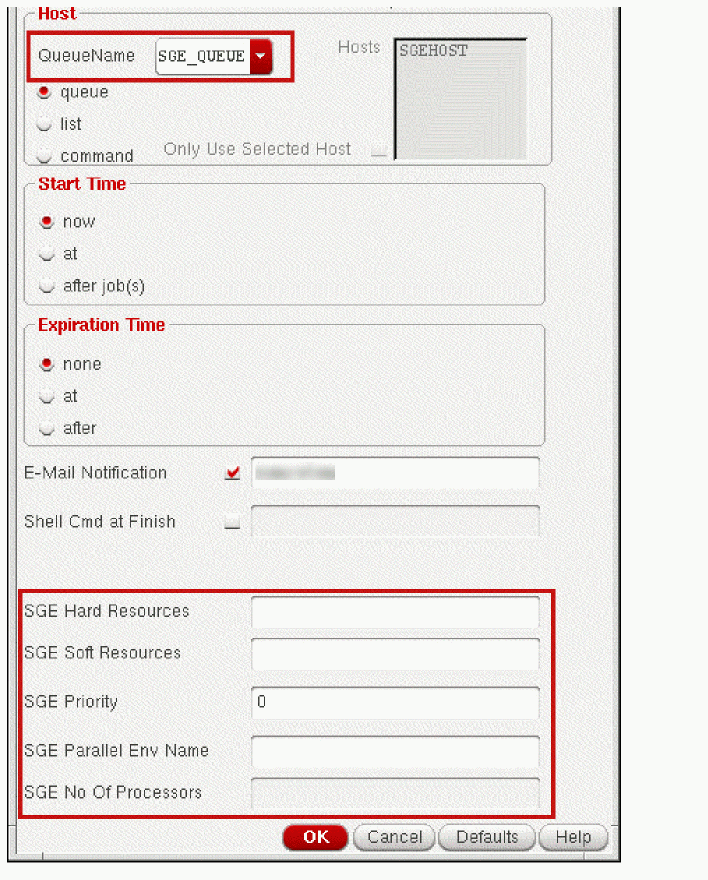
-
SGE Soft Resources: Specifies requirements for soft resources. You can specify values for
%MEM_ESTand%CPU_ESTin this field. -
SGE Hard Resources: Specifies requirements for hard resources. You can specify values for
%MEM_ESTand%CPU_ESTin this field. - SGE Priority: Specifies the priority of the submitted job.
- SGE Parallel Env Name: Specifies the name of a parallel environment.
-
SGE No Of Processors: Specifies the number of processors that you can use. Using this field, you can ensure that the job is run on a machine with sufficient number of CPUs available. You can also reserve these slots to stop many other jobs running on the same machine.
Validating the LBS Distributed Processing Setup
To enable the distributed processing method, you need to specify a significant number of settings. Specifying the correct settings ensures that the setup is valid and appropriate messages are generated.
-
Choose Setup – Job Setup in ADE Explorer, or Options – Job Setup in ADE Assembler.
The Job Policy Setup form appears.
The Job Policy Setup form tests the setup for enabling distributed processing and performs several checks to ensure that the distributed processing environment is set up correctly. The Job Policy Setup ensures the following:
- If the environment variables needed for distributed processing are set properly.
- If the LSF settings are correct, when you select LSF as the distribution method. It also verifies if you have set the path properly and the installed LSF version is supported.
-
If the machines mentioned in the LBS queue are active and
cdsqmgrDRMS is running on the cluster master machine. It also verifies the hierarchy setup for the machines in queue.
The Job Policy Setup performs all the specified checks and displays an appropriate Error or Warning message, if required. If an error occurs, it quits the subsequent checking, but continues to submit jobs with warnings. The Job Policy Setup uses rsh and remsh commands internally for performing the above mentioned checks. Therefore, you must ensure that these commands are run without a password. The Job Policy Setup performs only static checks. It does not submit test jobs to validate the setup.
echo or stty command in your shell setup files because the check utility will not work properly if echo or stty commands exist in your shell setup files.Submitting Simulation Jobs in LBS Distribution Method
In distributed processing, the order of unused processing capacity of a job determines its assignment to a machine. The job-limit of the job has no impact on this assignment. Hence, when you use a DRMS such as LSF, distributed processing may send jobs to different machines in a different order, as compared to the jobs it sends without LSF.
In distributed processing, you can submit a job from one machine to another. These machines must have access to Cadence software, but they do not need to be in a predefined queue. For example, when you use the distributed processing mode with LSF, both the machines – the machine that you are submitting the job from and the machine running the job – must be in the cluster that has the license to use LSF.
When a job fails using the on of the supported DRMS, all its dependent jobs fail too. Jobs dependent on other jobs that fail are held in the DRMS database indefinitely until you use a DRMS command to force the job to run.
You can submit simulation jobs for distributed processing in one of the following ways:
- Using the ADE Assembler Graphical User Interface
- Using OCEAN
- Using Command-Line Mode
Submitting Distributed Processing Jobs
To use distributed processing in ADE Explorer or ADE Assembler, you need the following:
- Load Balancing Software (LBS) to monitor the activity on the machines that you use for simulations. To know more about a default LBS setup, see System Requirements for cdsqmgr Setup.
- Job Policy Setup form lets you specify the time, the queue, or host for submitting your distributed job.
- Job Monitor form lets you view, suspend, resume, or kill jobs.
Additionally, command-line job submission and monitoring from the UNIX terminal window lets you submit, suspend, resume, monitor, or kill jobs.
You can submit simulation jobs using the Job Policy Setup form in ADE Assembler and ADE Explorer.
- To know more about submitting jobs in ADE Assembler, see Starting a Simulation.
- To know more about submitting jobs in ADE Explorer, see Starting a Simulation.
Submitting Distributed Processing Jobs in OCEAN
This section describes how you can submit a distributed job using the Open Command Environment for Analysis (OCEAN). See the following sections:
- Preparing the OCEAN Environment for Distributed Processing
- Submitting a Job in OCEAN
- Selecting Results by Job Name
- Viewing Results
For more information, see the OCEAN Reference.
Preparing the OCEAN Environment for Distributed Processing
This section describes the basics of setting up OCEAN to use distributed processing. For detailed information on distributed processing commands in OCEAN, see the
To use OCEAN for distributing jobs, you must do the following:
- Start OCEAN.
- Enable distributed processing in OCEAN.
- Disable distributed processing in OCEAN, when required.
Starting OCEAN
To start OCEAN, type the following at the command line of your terminal window:
>> ocean
Enabling Distributed Processing in OCEAN
To enable distributed processing, do one of the following:
-
Type the following at the command line:
>> hostMode( ’distributed )
-
Set the
asimenv.startuphostMode environment variable todistributedin the.cdsenvfile.
Disabling Distributed Processing in OCEAN
To disable distributed processing, type the following at the command line of your terminal window:
>> hostMode( ’local )
Submitting a Job in OCEAN
To submit a job, use the run command, as follows:
>> ocean> run()
The job is submitted, and if the submission is successful, the jobName is returned. After you submit the job, use simJobMonitor to monitor the status of your job.
The terminal window running OCEAN may display the following message:
Job ‘job004’ ran on ’tez’ and completed successfully
This message notifies you about the completion of a job. To turn off display of such messages, set the asimenv.startup showMessages environment variable to nil in your .cdsenv file.
Selecting Results by Job Name
To access results based on the job name, type the following on the OCEAN terminal:
>> openResults( jobName )
This is equivalent to calling openResults with a results directory path.
Example
openResults( ’job001)
The preceeding command opens the results of job001.
Viewing Results
Distributed processing in ADE Explorer or ADE Assembler creates a unique directory structure to contain your results. The results are stored in the following location on the submission host:
simulation/cell_name/simulator/schematic/distributed/job_name/psf
If you are using parametric analysis, the results are saved in the /param directory instead of the /distributed directory.
To know more about OCEAN commands for distributed processing, see the OCEAN Reference.
Submitting Distributed Jobs in LBS using the Command Mode
The command option is meant for the advanced users who have full understanding of the DRMS (Distributed Resource Management System) commands and their corresponding syntax and options. Ensure that you enter a valid DRMS command to submit the job. The environment does not validate or check the command for errors because it assumes that any DRMS command that you enter is valid.
The command mode supports all DRMSs, especially LSF and SGE, that provide a command-line interface of the type <job_submission_command job_command>.
In general, the following assumptions are made about the command-line interface of the DRMS:
- The DRMS command-line interface accepts a single string as a job command. This string is the last argument of the job submission command.
- The DRMS job submission command is a non-blocking command. This means that the job submission command exits after queuing the job into the DRMS and does not wait for the job to complete.
-
The DRMS job submission command returns the value
0upon successful submission of the job. A non-zero return value indicates an error in job submission.
To use only the DRMS command mode for distributed processing, skip setting the value for LBS_BASE_SYSTEM and LBS_CLUSTER_MASTER.
Monitoring Distributed Jobs in LBS Method
The job monitor lets you view the status of submitted jobs. Using the Job Monitor, you can view the active jobs, save configurations, view log files, set job monitor options, set filters, or view job properties. For more information, see the Cadence® Job Monitor Reference.
Debugging an LBS Distributed Processing Setup
You can debug your distributed processing setup based on the DRMS that you use.
Debugging LBS with cdsqmgr
In case of errors while running LBS with cdsqmgr, do the following:
-
Check that all the submission hosts and execution hosts pass the
checkSysConftest. IfcheckSysConffails, install the missing OS patches reported. You need to do this check for all IC tools and simulators that you run. -
Check if the
/etc/hostsfile is set up properly. For example: -
Check if
cdsqmgrhas been started from the root. In the Unix terminal, use theps -eafcommand as follows:
ps -eaf | grep cdsqmgr -
Run the following command to check if
LBS_CLUSTER_MASTERis set correctly. It must point to the host on whichcdsqmgris running.
echo $LBS_CLUSTER_MASTER -
5. Check that the
LBS_BASE_SYSTEMvariable is not set in your environment. On typing the following command, your system must returnUndefined variable:
echo $LBS_BASE_SYSTEM - Ensure that the remote hosts can access the path to the design libraries, the project directory, and the path from where you launch Virtuoso.
-
Restart
cdsqmgrif any information in the config file (lbs.config) contains updates, to make the changes effective for all users. For this, kill any runningcdsqmgrandcdsNameServerprocess onhostAand startcdsqmgragain.
Debugging LBS with Third-Party DRMS
You can debug the LBS settings based on the third-party DRMS that you choose for distributed processing of yours jobs. See
Troubleshooting FAQs
This section describes how to troubleshoot some of the common difficulties that you can experience while running distributed simulations. See the following problem statements and their corresponding solutions:
- Distributed processing does not work.
- I specify an LSF Resource Requirement String in the Job Policy Setup form and submit a job. The job does not run even after a long time, and I do not see any error message.
- I select LBS as the distribution method on the Job Policy Setup form, and the form expands, but I cannot use distributed processing.
- I start the Job Monitor but it is blank. There are no jobs listed.
- I name a job analysis2 and the system renames it to analysis2001.
- The machine I want to use is not in the host list on the Job Policy Setup form.
- When I click Run, I get a long error message that says that I cannot connect to the LBS queue manager.
- When I run a distributed simulation, I get an error message saying that the job submission failed.
- When I submit a job, it fails and comes back with an error message such as
- I made job B dependent on job A. Job A ran, but job B did not. What is wrong?
- My simulation finished, but I cannot find the PSF results.
- I am using LSF with the distributed processing mode. When I try to run my jobs, I get an error message – “LSF setup is not proper”. I cannot submit any jobs.
- The distributed processing mode randomly quits working. My jobs fail and I get an error message – “Could not connect to the LBS queue manager”. I usually keep a design framework II session running all night.
- I am able to successfully submit distributed processing jobs to all hosts except the cluster master machine, even though it is in one of the cluster’s queues. The job status says: "Job dispatch failed; Cluster master timed out on ACK from execution host".
- I encountered an error message containing a numeric identifier. For example:
- What does this numeric identifier signify?
- How do I specify a queue for a put together job?
- LSF shutdown causes job distribution to freeze?
- When I run a simulation successfully using LSF on Linux, and add new queues, the new queues do not reflect in the Job Policy Setup form.
Distributed processing does not work.
Use the following general troubleshooting tips as one of these could be the reason for the problem in a distributed processing run:
-
Ensure that when you use
rloginfor logging in to remote hosts, you do not receive a password prompt. Authenticate the submission host as a trusted host by usingxhost. Alternatively, create an.rhostsfile in the home directory and ensure that it contains a ‘+’ character. - Ensure that the remote hosts can access the paths to all the model files and the simulation directory.
-
Ensure that the remote hosts can access the Cadence tools hierarchy. To do this, use
rloginfor logging in to the remote host. Run the following command and check if it returns the path to the Cadence hierarchy:unix> which virtuoso
-
Ensure that a user submitting a job has an account and a home directory on the submission host and the execution host.
For example, if a user submits a job from machine A to machine B but does not have an account on machine B, the submit request fails. - Ensure that the directory on your local machine from which you run the distributed processing software is exported.
-
Ensure that the uid (UNIX user ID) of a user does not change as the user switches from one machine to another. For example, if the user
morrisonhas uid8819on machine A, another userdoecannot use uid8819on machine B. -
Ensure that all users who want to submit jobs have write-access to the
/tmpfile system on the execution and submission hosts. The host machines use this file system to save certain temporary files that are created as a result of the submission and execution processes. -
Ensure that the directory structure on the home machine and the remote machine is identical. For example, if the job’s working directory on your machine is
/net/salmon/u1/morrison, the design directory on the execution machine must be/net/coho/u1/morrison. If the directory structure onsalmondoes not match that oncoho, use a link to mirror the directory structure on the home machine. - Ensure that you specify the correct file paths. Distributed processing considers all files – input, output, error, and any command or OCEAN files – to have absolute or relative locations, depending on whether they are preceded by a forward slash (/). If relative, their location is searched relative to the working directory of the job.
I specify an LSF Resource Requirement String in the Job Policy Setup form and submit a job. The job does not run even after a long time, and I do not see any error message.
This can happen if you specify a resource requirement that is not possible to implement or conflicts with an existing option in the Job Policy Setup form. In such a case, run xlsbatch from the UNIX prompt to monitor the status of your job. xlsbatch is a job monitoring tool provided by IBM. To know more details, refer to the
The status of a job may remain PEND for a long time because of a complication associated with the LSF Resource Requirement String. In the job details of xlsbatch, the PENDING REASON indicates why the job is in a PEND state. You can resolve this by modifying some of the job properties using Job – Manipulate – Modify in xlsbatch.
I select LBS as the distribution method on the Job Policy Setup form, and the form expands, but I cannot use distributed processing.
Distributed processing is available for the Spectre simulator and all the simulators integrated using OASIS. Ensure that you set the appropriate simulator in ADE Explorer or ADE Assembler. See the Command Interface Window (CIW) for error messages or warnings.
I start the Job Monitor but it is blank. There are no jobs listed.
This might be normal. The Job Monitor may not show any job for the following reasons:
- You have not started any jobs yet.
- You started jobs, but a long duration has elapsed and the jobs are finished and consequently terminated.
- The Job Monitor lists jobs by queue, usually in one queue at a time. If you are unsure about the queue that contains your jobs, select ALL under the Queues tab.
I name a job analysis2 and the system renames it to analysis2001.
This indicates that a job analysis2 already exists in the same session. The distributed processing environment automatically appends a three-digit number to any duplicate job names to keep them unique.
The machine I want to use is not in the host list on the Job Policy Setup form.
Contact your system administrator, or cluster master operator, to add the machine to a queue. You can use the list field in the Job Policy Setup form to specify the machine you want to use.
When I click Run, I get a long error message that says that I cannot connect to the LBS queue manager.
Log on to the distributed processing cluster master and list the running processes. Find and kill the cdsqmgr process running under your user name. If you find this process, kill it.
Verify that a cdsqmgr is running under root. If it is not running, contact the cluster operator to restart it.
Exit the Cadence® software on your local host, and then restart it.
You can also get this error when you do not set your environment variables properly. Make sure that LBS_BASE_SYSTEM and LBS_CLUSTER_MASTER are set properly. Also verify that the master host is only in one cluster.
When I run a distributed simulation, I get an error message saying that the job submission failed.
Several situations can cause this error message:
- You do not have an account on the machine to which your job is submitted.
- The specified machine is disconnected from the network or shut down.
- The remote machine does not have access to the Cadence software, especially the distributed processing DRMS. By default, the local setting of the path environment variable should be valid for each execution host.
When I submit a job, it fails and comes back with an error message such as
sh: ./runSpectre not found, spectre not found.
The simulation fails because the remote job cannot find the simulator. You must have a path to the Cadence software on each of the remote machines. By default, distributed processing uses your local environment settings to initialize the session on the remote host. The search path on the remote host will be the same as the path setting on your local host. You must ensure that the path setting on the remote host is relevant, else the simulator will not be found.
For example, on your home machine you have a link to the Cadence software at /u1/users/bill/Cadence. However, your account is at /usr1/mnt3/bill on the machine that you run your job. The remote job goes to /u1/users/bill/Cadence/tools/dfII/bin on the remote machine and finds no account. You must either move the account to /u1/users, to match your home machine, or create a link from /u1/users to /user1/mnt3.
I made job B dependent on job A. Job A ran, but job B did not. What is wrong?
The dependency feature is not based on whether a job runs, but whether the simulation succeeds. If the simulation fails, subsequent dependent jobs will not run.
My simulation finished, but I cannot find the PSF results.
Distributed processing does not store its results in the standard /psf directory. Instead, it creates a /distributed directory at the same level as /psf and /netlist. The /distributed directory contains a directory for each job. This directory contains the /netlist and /psf directory for each job.
I am using LSF with the distributed processing mode. When I try to run my jobs, I get an error message – “LSF setup is not proper”. I cannot submit any jobs.
When you use LSF, both the machines – the machine you are submitting the job from, and the machine you are submitting the job to – must be in the predefined LSF cluster. The scenario that you describe occurs if your home machine, or the machine that you are submitting from, is not in the LSF machine cluster.
The distributed processing mode randomly quits working. My jobs fail and I get an error message – “Could not connect to the LBS queue manager”. I usually keep a design framework II session running all night.
The most likely reason is that your system administrator is making changes to the job queue. These changes may include changes to the depth or nature of the queue, or to the list of machines included in the queue. Each time the system administrator makes such changes this, they must shut down the Cadence Queue Manager (cdsqmgr). This disrupts any distributed jobs that you have in progress. You must exit your Cadence session and start again.
I am able to successfully submit distributed processing jobs to all hosts except the cluster master machine, even though it is in one of the cluster’s queues. The job status says: "Job dispatch failed; Cluster master timed out on ACK from execution host".
Verify that when the cdsqmgr process starts on the cluster master, your PATH variable contains the path to the bin directory in the Cadence software hierarchy. This means that your PATH variable must contain CDS_INST_DIR/tools/bin).
I encountered an error message containing a numeric identifier. For example:
ERROR (28): There was an error connecting to the distributed job server service. This host may not be set up correctly for using Distributed Processing.
What does this numeric identifier signify?
Each error message in distributed processing is given a unique numeric identifier. You can use this numeric identifier to access extended help (if available) on an error message by typing the following in the CIW:
msgHelp <prodID> <errorID>
|
is the product ID. In case of distributed processing, it is |
|
|
is the error message ID number. This is the numeric identifier that is available in the error message box. |
msgHelp ’DP 28
This displays the extended help for the distributed processing error message, whose message ID is 28.
How do I specify a queue for a put together job?
You can specify a queue for a put together job by specifying an environment variable as follows:
asimenv.distributed puttogetherqueue string "" nil
LSF shutdown causes job distribution to freeze?
From the same terminal window that is running the workbench, kill the cdsfrb_lsf daemon and restart the workbench to get into distributed processing mode.
When I run a simulation successfully using LSF on Linux, and add new queues, the new queues do not reflect in the Job Policy Setup form.
Ensure that you set the environment variable as, LANG=’C’.
Return to top